随着Jetson TX2的发布,NVIDIA的野心也展露无遗——再次向AI应用环境边界进军,加速AI技术普及。
本文转自搜狐:NVIDIA进军AI边界,发布Jetson TX2计算模块
TX2性能分析
提到进军人工智能的NVIDIA,首先想到的或许是TITAN X、1080,或者更高端的DGX-1,这些“性能怪兽”是NVIDIA在人工智能市场的“主力军”。相比下,嵌入式的Jetson名声就要小的多,尺寸和功耗才是主要特性的它也瞄准了一个特殊的市场——嵌入式人工智能模块。
日前,NVIDIA发布了自家最新产品Jetson TX2。在继承前辈信用卡大小尺寸的同时,整体软硬件都获得了升级。

NVIDIA Jetson TX2
随着Jetson TX2的发布,NVIDIA的野心也展露无遗——再次向AI应用环境边界进军,加速AI技术普及。
硬件:性能整体提升超过2倍
与2015年11月发布的上一代产品Jetson TX1相比,Jetson TX2进行了全面的升级:
GPU:基于NVIDIA Pascal?架构的256核GPU可提供一流的性能
CPU:双核64位NVIDIA Denver 2、四核 ARM® A57
视频:4K x 2K 60fps编解码
摄像机:12路CSI通道,最多支持6个摄像机;2.5千兆字节/秒/通道
内存:8GB LPDDR4;58.3千兆字节/秒
存储:32GB eMMC
连接:802.11ac WLAN、蓝牙
网络:1GB以太网
操作系统支持:适用于Tegra®的Linux
GPU方面从之前的Maxwell架构升级为Pascal架构,虽然内部处理器数量没变,但是同频率下性能提升接近50%(根据GTX1080/980的浮点运算能力与流处理器数量对比估计)。同时Pascal还采用了最细的16nm工艺制程,发热量、功耗肯定有所缩减。
CPU方面也迎来了一次直接升级:在Jetson TX1原有的四核“64-bit ARM A57核心”的基础上添加了两颗NVIDIA自家研制的“64-bit Denver 2核心”。在单核性能上,Denver2比A57还会更胜一筹,这也意味着CPU的预期提升也将超过50%。性能提升的直接结果是,视频压缩能力从TX1的2160p@30提升到了2016p@60。
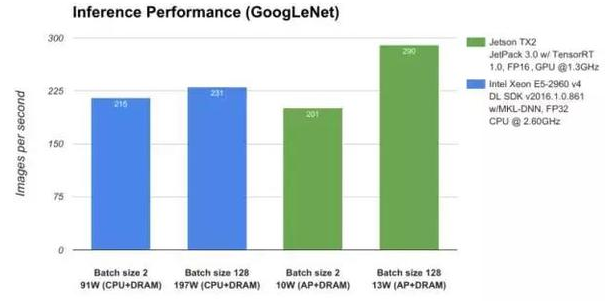
Jetson TX2 vs E5-2690 v4(图中CPU型号错误)
外国首批拿到Jetson TX2的媒体还进行了上手测试,在人工智能应用上,TX2的表现升值超过了Intel Xeon E5-2690 v4。要知道,后者是一颗14核28线程的服务器CPU,TDP(热功耗)高达135W。最终的结果是,TX2不仅运算能力更强,而且功耗远远低于前者。
在其他组件方面,Jetson TX2也有所提升,内存从原来的单通道4GB LPDDR4升级为双通道8GB LPDDR4,内存带宽从原来的25.6GB/s暴涨至58.4GB/s。这也意味着内存的工作频率同样有所提升。

同时,NVIDIA还在Jetson TX2上加入了两种全新模式:MAX-Q、MAX-P。MAX-Q模式将能效比放在最重要的地位,整体功率小于7.5瓦,远小于绝大部分移动CPU产品,最终实现两倍于TX1的能效比。
MAX-P模式则能将性能最大化,这个模式下功耗有所增加,但依然小于15W,而且这个时候你将获得两倍于TX1的实际性能。开发者可以根据自己的需求选择适合的工作模式。
软件:外层系统跃进

与Jetson TX2一同更新的还有它所依赖的整个开发环境——Jetpack3.0。后者作为NVIDIA提供的一整套Jetson开发工具,为人工智能提供了一整套软件架构。
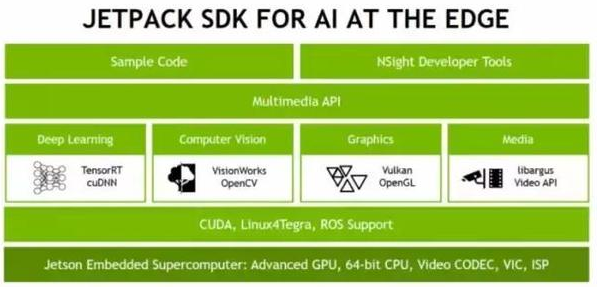
从对接硬件的CUDA、Linux4Tegra、ROS Support,再到针对4大应用场景分化出来的底层API:深度学习的TensorRT、cuDNN;机器视觉的VisionWorks、OpenCV;图像渲染的Vulkan、OpenGL;多媒体的libargus、Video API。
在这些基础之上,NVIDIA还打造了一套通用化的Multimedia API,同时在它之上努力实现开发代码简化和打造专用开发工具NSight Developer Tools。
Jetpack近几年的发展路线正好按照这个架构从下而上进行:2015年11月通过更新硬件和底层API,让人工智能应用的能效比提升了10倍。2016年9月更新的Jetpack2.3支持了更多的API、所有API几乎都来了一次升级。
新发布的Jetpack3.0则将升级重点放在了外部系统层级:Linux Kernel升级到4.4,Mutimedia API升级到27.1。
这就好比一个修炼好内功的武林高手,开始寻找更适合自己发挥的平台。

值得注意的是,Jetpack 3.0的架构同样具有一定的通用性,你在Jetson TX2上所付出的的开发工作同样适用于NVIDIA更加强力的其他硬件。因为用户目前在这些应用场景中只有Jetson可以选择,那么同时配合NVIDIA其他硬件也是顺理成章的事。
这也是为什么NVIDIA在官方讲解中也提及了Jetson与自家其他硬件在云端的互通互联。安放在汽车、无人机、摄像头端的Jetson可以与NVIDIA或者第三方设置在云端的Tesla显卡、DGX-1计算模块进行必要的协作,从而最大程度释放能力。
根据NVIDIA官方公布的信息,Jetson TX2开发套件(包括开发板和TX2模块)今日起已经在美国和欧洲接受预定,零售价格599美元,教育售价299美元(5折),并且会按照订单情况从3月14日开始发货。其他国家的发售将安排在4月份。
最终需要嵌入到其他产品中的Jetson TX2模块也公布了官方售价:1000件以上售价399美元。发售日期将安排在今年的第二季度,发售地区也将覆盖全世界。Jetson TX1开发套件价格也随之做了个小调整:下调至499美元。
Jetson实例:实时手持建模、商店机器人
在Jetson TX2发布的同时,NVIDIA也在官网的微博中分享了两个Jetson TX1计算模块的应用实例。
第一个是Artec 3D的Leo 3D扫描仪,这也是目前最先进的手持3D扫描仪。它长着的两个“大眼睛”,可以直接将035-1.2m物体建模,并且将贴图一并处理。整个过程跟你拿着摄像机拍电影没什么区别。

Leo 3D扫描仪
同时它还能在触摸屏上直接看到实时生成的3D建模结果,你还能通过触摸屏旋转3D模型,检查已经生成的模型,发现之前捕捉遗漏的位置,直接进行补充。
这种快速成型的能力,让Artec Leo在工业设计和制造、医疗卫生、科技教育、艺术保护方面有很多应用空间。
出色的性能来自Artec Leo内置的就是Jetson TX1计算模块。相比Artec自家上一代产品,Leo扫描物体体积增大了将近3倍、同时在3D分辨率精度、纹理分辨率、3D重建速率等方面都获得了充足提升。而这一切还是建立在手持、无需外部电源的基础之上。
另外一个案例则是款机器人——Fellow Robots出品的LoweBot NAVii?。正如其名,这款机器人为美国第二大五金零售商Lowe’s打造。

LoweBot NAVii?
它的主要功能有两个,一是在客户提供需求之后,带路前往商品所在的货架。另外一个则更重要,NAVii机器人会持续地对货架上的商品进行图像扫描、识别,整体统筹商品的数量。店面人员也能够从商品数量核对的工作中释放出来,并且将很多的时间用以服务客户,满足他们各种各样的需求。驱动NAVii机器人的,实际上也是Jetson TX1模块。
专注AI应用边缘
在这次发布Jetson TX2发布之前,NVIDIA的人工智能硬件布局已经颇有建树:自动驾驶领域的Drive CX/PX/PX2/PX AC,专业性能显卡新TITAN X以及其他GTX显卡、最后是威力最强的小型“超级计算机”DGX-1。
为什么有了这么多性能更强劲的硬件,NVIDIA还要出这样一款尺寸只有信用卡大小的产品呢?这一点实际上出自NVIDIA本身对于人工智能使用环境的思考——AI的应用边缘非常重要,它不仅是个市场,还能推动人工智能技术的普及。
NVIDIA在官方介绍中也举了4个了例子:
(1)到2020年,全世界将拥有超过10亿个摄像头,他们每天产生的数据将达到数十PB(1PB=1000TB),为了传输这些数据需要大量的带宽;
(2)工业检测环节通过拍照鉴别产品质量,但由于空间和操作机构的关系,整个过程只能有200ms的延迟,每秒还要处理30张以上的图片;
(3)在医疗等领域,患者的信息非常重要,与其将患者的信息上传到网络上进行处理,不如直接在本地进行处理和存储;
(4)全球有超过50%的地方无线网络速度小于8mbps,这也限制了我们利用无线网络链接到云端的计算资源。
很容易发现,NVIDIA这次提出的例子都非常“具体”,比如第二个工业环节的检测。工业生产中数量很大,大批量的产品通过高速传送带运输。但在这个过程中,高速摄像机要拍到每一个产品,并且根据拍到的图像去判断产品的优劣,同时还要在最短的时间内变成实际动作,将残次品挑出去。

在这样实际的案例和NVIDIA目前打造出来的整个人工智能世界之间,恰恰存在一道不算宽、但的确阻碍的峡谷,将人工智能技术拦在了在很多场景应用之外。而Jetson和配套的Jetpack扮演的角色就像一座一座“桥”,横跨在峡谷之间,尝试让人工智能技术跟更多的应用场景联系起来。
自然,桥越宽、越结实,人工智能技术也能适应更多应用场景的需求,并且在这些领域中发挥出人工智能技术应有的变革力量。
NVIDIA的老策略:培育市场就是占领市场

从客观角度来审视人工智能技术,整体进程与通讯技术早期发展有很多相似之处,从最早的电报,再到接线员,然后到寻呼机、大哥大,再到最后的手机、智能手机。
虽然远距离通信技术诞生已久,但在手机、乃至智能手机出现之前,这个市场整体容量并不大。虽然大哥大或许单品价值更高,但摩托罗拉和诺基亚的最辉煌时期还是建立在庞大的手机市场之上。
这个规律同样适用于人工智能技术。虽然人们现在已经发现人工智能技术能够带来改变,但是在他们能够比较容易、或者很容易获得变革之前,他们还是偏向于寻找其他更老、同时看起来更可靠的解决方案。
而Jetson的成长过程也是如此——一方面不断提升硬件性能,一方面不断降低开发者的成本。究竟什么时候Jetson能够达到市场所需要的水平?没人知道,但如果NVIDIA自己不做这件事,人工智能的嵌入拓展或许必须等到市场需求的进一步积累。
NVIDIA最终选择了——用自己的力量推动技术发展,最终催生出新的市场。
2006年开始打造CUDA微处理器架构,连读多年举办GTC(GPU Technology Coference),GPU并不是人工智能技术的唯一选择,NVIDIA通过努力让自己和人工智能技术牢牢地绑在了一起。
为了培育这个市场,NVIDIA所花费的精力很难统计,但最终也正因为长期培育市场的动作,人工智能技术才会像今天一样和NVIDIA紧密相关。
可以期待,随着Jetson TX2这样成本低、功耗小、开发容易、同时还能很容易布置到各种应用场景硬件端的人工智能运算硬件出现,人工智能技术有可能再次掀起一波普及。而随着星星点点应用场景的聚合,我们也将体会到人工智能时代真正的魅力。