详解CV领域中目标检测任务的评价指标(Recall,Precision,AP,mAP,IoU)
请再也不要凭你惊人的眼力断定一个算法的精度了好吗!
版权声明:本文为博主原创文章,未经博主允许不得转载。
吉娃娃与松饼
从一个细思极恐的分类问题出发~~~先放图~~~

此前有位神人发现了一个有趣的现象,吉娃娃与松饼的相似程度已经到了令人惊恐的程度…
这个图片在AI行业中流传甚广,区分吉娃娃与松饼这么有趣的问题,当然要交给万能的深度学习来解决!
一些定义
假设现有一个测试集,测试集如上图所示,图片只由吉娃娃与松饼组成
现提出一个分类任务:识别出测试集中所有吉娃娃的图片
作出如下定义
True positive:吉娃娃的图片被正确识别成了吉娃娃
False positive:松饼的图片被错误识别成了吉娃娃
True negative:松饼的图片没有被识别出来,系统正确地认为它们是松饼
False negative:吉娃娃的图片没有被识别出来,系统错误地认为它们是松饼
Precision与Recall
Precision(精确率)其实就是在识别出来的图片中,True positives所占的比率:
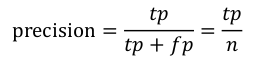
其中的n代表的是(True positives + False positives),也就是系统一共识别出来多少照片是吉娃娃。
Recall(召回率)是被正确识别出来的吉娃娃个数与测试集中所有吉娃娃的个数的比值:
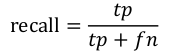
Recall的分母是(True positives + False negatives),这两个值的和,可以理解为一共有多少张吉娃娃的照片。
Precision-Recall关系图绘制
通过调整识别阈值,来选择让系统识别出多少图片,进而改变Precision或 Recall的值。
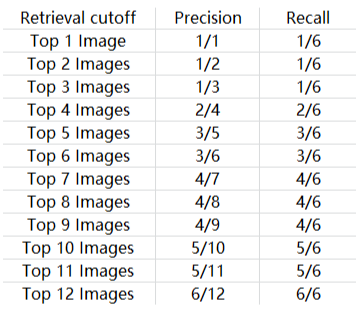
如下图所示,对测试集中的图片进行编号

假设改变识别阈值,使得系统依次能够识别前K张图片(K=1,2…,12),阈值的变化同时会导致Precision与Recall值发生变化。
具体变化情况如下表:
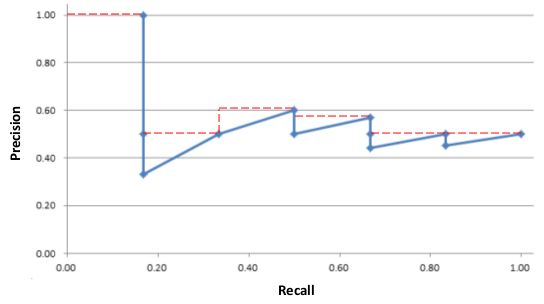
以Recall值为横轴,Precision值为纵轴绘制Precision-Recall曲线如下图:
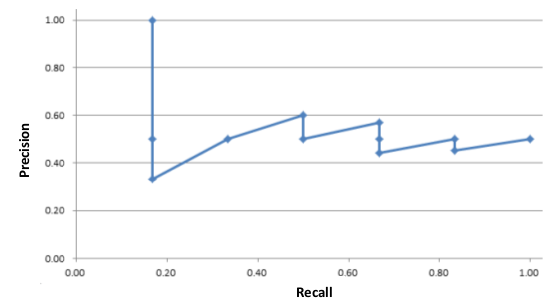
若想评估一个分类器的性能,一个比较好的方法就是:观察当阈值变化时,Precision与Recall值的变化情况。
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
Approximated Average Precision
相比较与曲线图,在某些时候还是一个具体的数值能更直观地表现出分类器的性能。通常情况下都是用 Average Precision来作为这一度量标准,它的公式为:
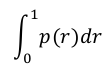
在这一积分中,其中p代表Precision ,r代表Recall,p是一个以r为参数的函数,That is equal to taking the area under the curve.
实际上这一积分极其接近于这一数值:对每一种阈值分别求(Precision值)乘以(Recall值的变化情况),再把所有阈值下求得的乘积值进行累加。公式如下:
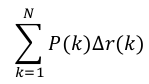
在这一公式中,N代表测试集中所有图片的个数,P(k)表示在能识别出k个图片的时候Precision的值,而 Delta r(k) 则表示识别图片个数从k-1变化到k时(通过调整阈值)Recall值的变化情况。
在这一例子中,Approximated Average Precision的值
=(1*(1/6-0)) + (1/2*(1/6-1/6)) + (1/3*(1/6-1/6)) + (1/2*(1/3-1/6)) + (3/5*(1/2-1/3)) + (1/2*(1/2-1/2)) + (4/7*(2/3-1/2)) + (1/2*(2/3-2/3)) + (4/9*(2/3-2/3)) + (1/2*(5/6-2/3)) + (5/11*(5/6-5/6)) + (1/2*(1-5/6))
=(1*(1/6)) + (1/2*0) + (1/3*0) + (1/2*(1/6)) + (3/5*(1/6)) + (1/2*0) + (4/7*(1/6)) + (1/2*0) + (4/9*0) + (1/2*(1/6)) + (5/11*0) + (1/2*(1/6))
=0.663
通过计算可以看到,那些Recall值没有变化的地方(红色数值),对增加Average Precision值没有贡献。
Interpolated Average Precision
不同于Approximated Average Precision,一些作者选择另一种度量性能的标准:Interpolated Average Precision。
假设当前识别出k个图片,则使用识别图片数大于k时最大的Precision值与Recall的变化值相乘。公式如下:
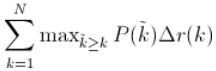
一些很重要的文章都是用Interpolated Average Precision 作为度量方法,并且直接称算出的值为Average Precision 。PASCAL Visual Objects Challenge从2007年开始就是用这一度量制度,他们认为这一方法能有效地减少Precision-recall 曲线中的抖动。所以在比较文章中Average Precision 值的时候,最好先弄清楚它们使用的是那种度量方式。
单图多目标的情况
上面吉娃娃与松饼的例子属于单标签分类问题,即每张图只存在一个目标。
当一张图中存在多个种类数不定的目标时,对每种目标单独计算Precision和Recall
如A类目标的Precision就是在识别出来所有A目标中,识别正确的比率;
A类目标的Recall就是在测试集里所有的A目标中,识别正确的比率;
mean Average Precision(mAP)

每一个类别都可以根据recall和precision绘制一条曲线,那么AP就是该曲线下的面积,而mAP是多个类别AP的平均值,这个值介于0到1之间,且越大越好。这个指标是目标检测算法最为重要的一个。
IoU
IoU可以理解为系统预测出来的框与原来图片中标记的框的重合程度。

绿色框是人工标注的groundtruth,红色框是目标检测算法最终给出的结果,显然绿色框对于飞机这个物体检测的更加准确(机翼机尾都全部包含在绿色框中),IOU正是表达这种bounding box和groundtruth的差异的指标。算法产生的bbox VS 人工标注的数据
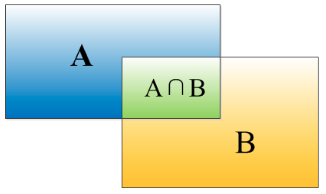
OU定义了两个bounding box的重叠度,可以说,当算法给出的框和人工标注的框差异很小时,或者说重叠度很大时,可以说算法产生的boundingbox就很准确。
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
恐怖系列
推特账号teenybiscuit的作品








参考链接:
【1】目标检测(一)目标检测评价指标-CSDN
【2】目标检测研究综述+LocNet: Improving Localization Accuracy for Object Detection CVPR2016 阅读-简书