K均值聚类与PCA算法详解
K均值聚类
聚类是一种无监督学习,它将相似的对象归到同一个簇中。
聚类与分类不同之处在于,分类的目标事先已知,而聚类不一样,类别没有事先定义。
K均值是发现给定数据集的K个簇的算法。簇个数K是用户给定的,每一个簇通过其质心,即簇中所有点的中心来描述
具体实现
思想
1.随机确定K个初始点为作为质心,然后将数据集中的每个点分配到每一个簇中,具体来讲,为每个点找距离其最近的质心,并将其分配给质心所对应的簇。
2.将每个簇的质心更新为该簇所有点的平均值。
迭代至簇不发生变化或达到最大迭代次数
|
|
这里的重新计算每个簇的质心,如何计算的是根据目标函数得来的,因此在开始时我们要考虑距离度量和目标函数。
考虑欧几里得距离的数据,使用误差平方和(Sum of the Squared Error,SSE)作为聚类的目标函数,目标是使得SSE最小。
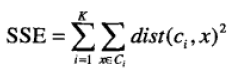
k表示k个聚类中心,ci表示第几个中心,dist表示的是欧几里得距离。
K均值算法缺陷
1.在大规模数据集上收敛较慢
2.K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的
3.K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同
4.K均值算法并不适合所有的数据类型。它不能处理非球形簇、不同尺寸和不同密度的簇
5.当初始质心是随机的进行初始化的时候,K均值的每次运行将会产生不同的SSE,而且随机的选择初始质心结果可能很糟糕,可能只能得到局部的最优解,而无法得到全局的最优解。
K均值优化算法(二分K-means)
为了克服K-Means算法收敛于局部最小值的问题,提出了一种二分K-均值(bisecting K-means)
算法的伪代码如下
数据降维
在原始的高维空间中,包含冗余信息和噪声信息,会在实际应用中引入误差,影响准确率;
而降维可以提取数据内部的本质结构,减少冗余信息和噪声信息造成的误差,提高应用中的精度。
数据降维的算法主要有主成分分析,等距映射,局部线性嵌入等
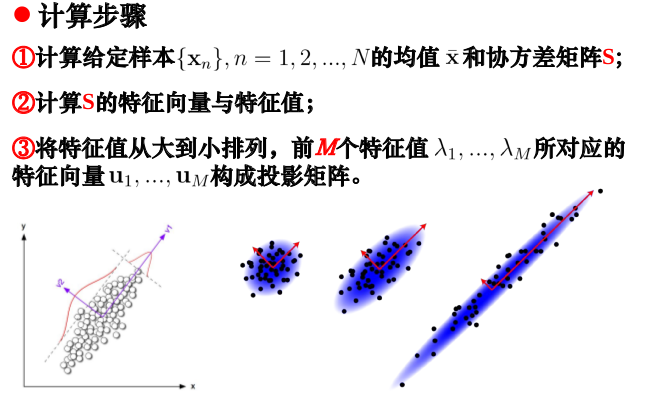
主成分分析算法
Principal Component Analysis(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性,将数据的主成分(包含信息量大的维度)保留下来
最大方差思想:
选取数据差异最大的方向(方差最大的方向,方差反应的是数据与其方差(均值)之间的偏离程度,我们通常认为方差越大数据的信息量就越大)作为第一个主成分,第二个主成分选择方差次大的方向,并且与第一个主成分正交。不断重复这个过程直到找到n个主成分。



参考资料
【1】《机器学习实战》Peter Harrington(美) 人民邮电出版社
【2】深入理解K-Means
【3】-PCA数据降维:从代码到原理的深入解析
【4】四大机器学习降维方法