谈谈机器学习算法中的泛化与拟合。
目标函数与逼近
监督式机器学习通常理解为逼近一个目标函数f,此函数映射输入变量X到输出变量Y。
Y=f(X)
这种特性描述可以用于定义分类和预测问题和机器学习算法的领域。
从训练数据中学习目标函数的过程中,我们必须考虑的问题是模型在预测新数据时的泛化性能。泛化好坏是很重要的,因为我们收集到的数据只是样本,其带有噪音并且是不完全的。
泛化
(1)简单地说,泛化即是算法模型的通用性与适应性。
(2)详细一点,泛化即是模型学习到的概念在它处理没有遇见过的样本时的表现。
(3)好的机器学习模型的模板目标是:从问题领域内的训练数据到任意的数据上泛化性能良好,也就是模型能够精确预测没有见过的数据。
(4)在机器学习领域中,当我们讨论一个机器学习模型学习和泛化的好坏时,我们通常使用术语:过拟合和欠拟合.
(5)过拟合和欠拟合是机器学习算法表现差的两大原因。
统计学中的拟合
(1)在统计学中,拟合指的是逼近目标函数的远近程度。
(2)这个术语同样可以用于机器学习中,因为监督式机器学习算法的目标也是逼近一个未知的潜在映射函数,其把输入变量映射到输出变量。
(3)统计学将描述函数和目标函数逼近的吻合程度来描述拟合的好坏。
(4)这类理论中的一些在机器学习中也是有用的(例如,计算残差),但是一些技巧假设我们已经知道了我们要逼近的函数。这和机器学习的场景就不同了。
(5)如果我们已经知道了目标函数的形式,我们将可以直接用它来做预测,而不是从一堆有噪音的数据中把它费力的学习出来。
机器学习中的过拟合
(1)过拟合指的是:模型对于训练数据拟合程度过当的情况。
(2)当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,就是过拟合。这意味着训练数据中的噪音或者随机波动也被当做概念被模型学习了。而问题就在于这些概念不适用于新的数据,从而导致模型泛化性能的变差。
(3)过拟合更可能在无参数非线性模型中发生,因为学习目标函数的过程是易变的具有弹性的。同样的,许多的无参数器学习算法也包括限制约束模型学习概念多少的参数或者技巧。
(4)例如,决策树就是一种无参数机器学习算法,非常有弹性并且容易受过拟合训练数据的影响。这种问题可以通过对学习过后的树进行剪枝来解决,这种方法就是为了移除一些其学习到的细节。
机器学习中的欠拟合
(1)欠拟合指的是模型在训练和预测时表现都不好的情况。
(2)欠拟合通常不被讨论,因为给定一个评估模型表现的指标的情况下,欠拟合很容易被发现。
(3)欠拟合的矫正方法是增加学习样本或者更换机器学习算法。
几个例子
这里引用斯坦福大学机器学习课程的几个例子加以说明:
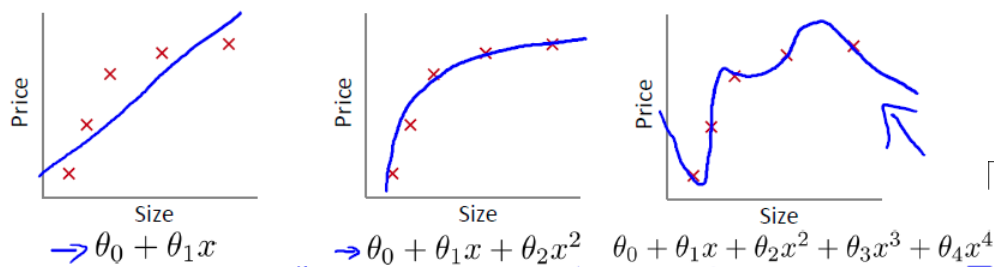
先看三张图片,这三张图片是线性回归模型拟合的函数和训练集的关系
1>第一张图片拟合的函数和训练集误差较大,我们称这种情况为欠拟合
2>第二张图片拟合的函数和训练集误差较小,我们称这种情况为合适拟合
3>第三张图片拟合的函数完美的匹配训练集数据,我们称这种情况为过拟合
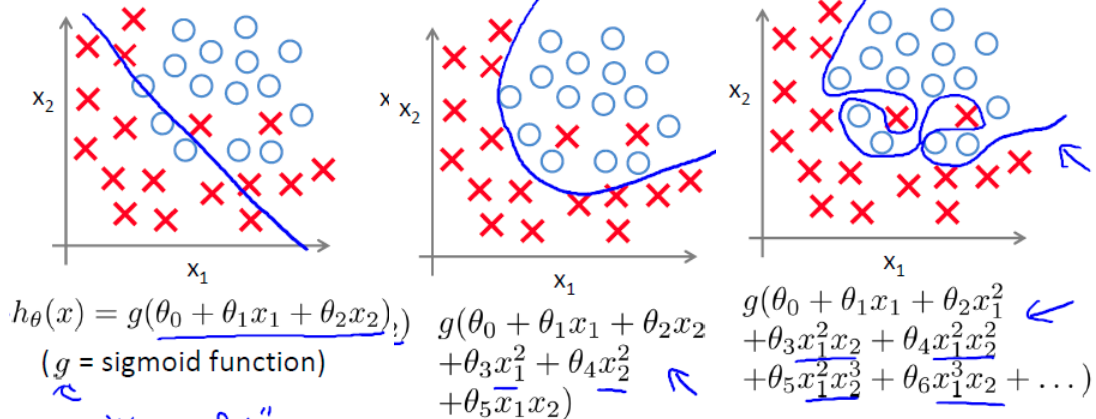
类似的,对于逻辑回归同样也存在欠拟合和过拟合问题,如下三张图
如何解决欠拟合与过拟合
(1)欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。
欠拟合问题可以通过增加特征维度来解决.(2)过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差。
解决过拟合问题,有3个途径:①减少特征维度,可以人工选择保留的特征,或者模型选择算法
②正则化,保留所有的特征,通过降低参数θ的值,来影响模型
③重采样,即交叉验证。最流行的重采样技术是k折交叉验证。指的是在训练数据的子集上训练和测试模型k次,同时建立对于机器学习模型在未知数据上表现的评估。
## 正则化
回到前面过拟合例子, h(x) = θ0 + θ1x1 + θ2x2 + θ3x3 + θ4x4
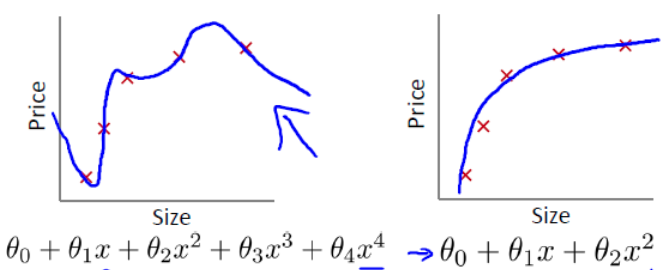
从图中可以看出,解决这个过拟合问题可以通过消除特征x3和x4的影响, 我们称为对参数的惩罚, 也就是使得参数θ3, θ4接近于0。
最简单的方法是对代价函数进行改造,例如
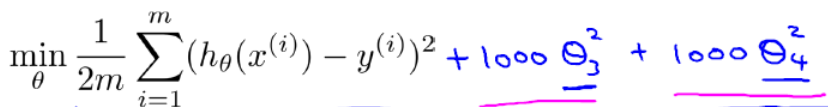
这样在求解最小化代价函数的时候使得参数θ3, θ4接近于0。正则化其实就是通过对参数θ的惩罚来影响整个模型.
k折交叉验证
这里详细介绍一下k折交叉验证,k-折交叉验证将样本集随机划分为k份,k-1份作为训练集,1份作为验证集,依次轮换训练集和验证集k次,验证误差最小的模型为所求模型。具体方法如下:
1>随机将样本集S划分成k个不相交的子集,每个子集中样本数量为m/k个,这些子集分别记作S1,S2…Sk;
2>对于每个模型,进行如下操作:
for j=1 to k
将S1 ∪…∪ Sj-1 ∪ Sj+1 ∪…∪ Sk作为训练集,训练模型Mi,得到相应的假设函数Hij。
再将Sj作为验证集,计算泛化误差W(Sj(Hij));
3>计算每个模型的平均泛化误差,选择泛化误差最小的模型Mi。
交叉验证是一种模型选择方法,其将样本的一部分用于训练,另一部分用于验证。因此不仅考虑了训练误差,同时也考虑了泛化误差。
参考:
【1】http://blog.csdn.net/u014696921/article/details/62883249
【2】http://blog.csdn.net/linkin1005/article/details/42869331