代码层面了解Faster R-CNN的实现细节, 重点RPN以及ROI pooling
前言
Faster R-CNN首次提出了anchor,使用RPN网络快速提取proposals,取代了耗时的selective search方法,大大提高检测效率.
Faster R-CNN的anchor思想被用于之后的YOLO和SSD等检测算法
关于Faster R-CNN的实现细节在下面的博客中已经做了介绍,本文主要从中抽取一些重点便于后面的回顾。
[Faster R-CNN基于代码实现的细节]https://blog.csdn.net/williamyi96/article/details/77648047
Faster R-CNN的基本结构
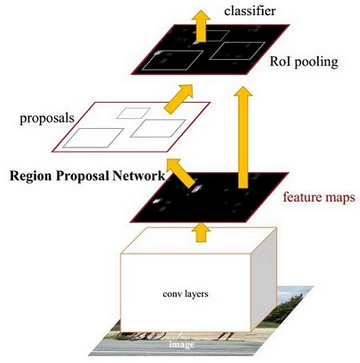
Faster R-CNN主要分为四个部分:
1.Conv layers. 使用一组基础的conv+relu+pooling层提取image的feature maps.
2.Region Proposal Networks. 该层生成一系列anchors并映射到原图,然后通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals.
3.Roi Pooling. 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature,送入后续全连接层判定目标类别.
4.Classification. 利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置.
下图展示了Python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构
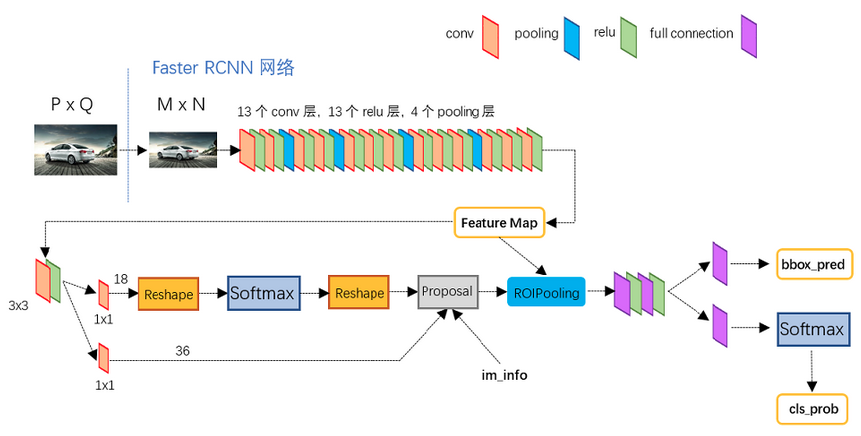
Conv layers
Conv layers部分共有13个conv层,13个relu层,4个pooling层
为保证Conv layers生成的featuure map中都可以和原图对应起来, 卷积过程中使用pad保证卷积后宽高不变, 经过一次pooling操作, 宽高变为原来的1/2.
一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16).
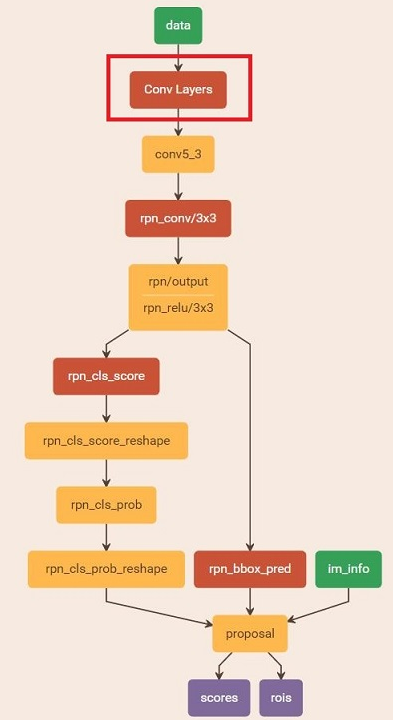
RPN
RPN网络结构如下图所示
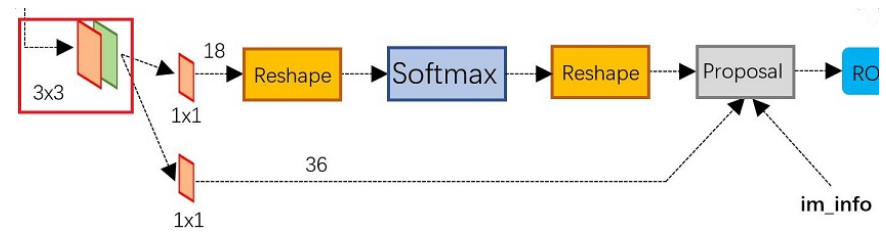
RPN网络实际分为2条线,上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground),下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。
最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。
其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
anchors
借用Faster RCNN论文中的原图,如下图,遍历Conv layers计算获得的feature maps,为每一个点都配备这9种anchors作为初始的检测框,后续通过边框回归可以修正检测框位置.
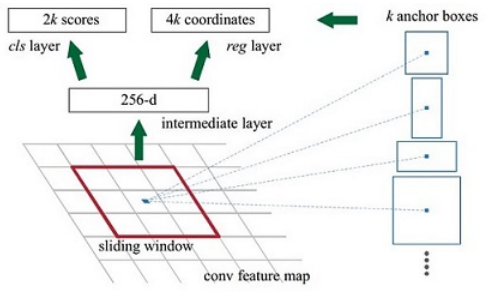
1.在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-d
2.rpn_conv/3x3卷积后,相当于每个点又融合了周围3x3的空间信息
3.假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
softmax判定foreground与background
在进入reshape与softmax之前,先做了1x1卷积

该1x1卷积的caffe prototxt定义如下:
该层输出:WxHx18
feature maps每一个点都有9个anchors,同时每个anchors又有可能是foreground和background
相当于初步提取了检测目标候选区域box(一般认为目标在foreground anchors中)
在softmax前后都接一个reshape layer目的是为了便于softmax分类
在caffe基本数据结构blob中以如下形式保存数据:
blob=[batch_size, channel,height,width]
对应至上面的保存bg/fg anchors的矩阵,其在caffe blob中的存储形式为[1, 2*9, H, W]。
caffe softmax_loss_layer.cpp的reshape函数的解释:
|
|
综上所述,RPN网络中利用anchors和softmax初步提取出foreground anchors作为候选区域。
边框回归
如下图,给定anchor A=(Ax, Ay, Aw, Ah),GT=[Gx, Gy, Gw, Gh],寻找一种变换F:使得F(Ax, Ay, Aw, Ah)=(G’x, G’y, G’w, G’h),其中(G’x, G’y, G’w, G’h)≈(Gx, Gy, Gw, Gh)。
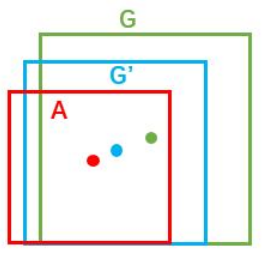
变换F的思路一般就是先做平移
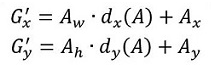
再做缩放
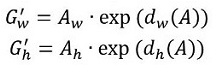
需要学习的是dx(A),dy(A),dw(A),dh(A)这四个变换
论文中的描述如下

接下来就是如何通过线性回归获得dx(A),dy(A),dw(A),dh(A)了(即tx,ty,tw,th)。
线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y非常接近,即Y=WX。
对于该问题,输入X是一张经过卷积获得的feature map,定义为Φ;同时还有训练传入的GT,即(gx, gy, gw, gh)。输出是dx(A),dy(A),dw(A),dh(A)四个变换。那么目标函数可以表示为:
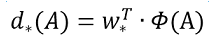
损失函数计算如下
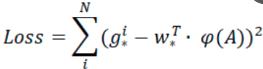
对proposals进行bounding box regression
来看RPN网络第二条线路

先来看一看上图中1x1卷积的caffe prototxt定义
|
|
可以看到其num_output=36,即经过该卷积输出图像为WxHx36,在caffe blob存储为[1, 36, H, W],这里相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的[dx(A),dy(A),dw(A),dh(A)]变换量
Proposal Layer
Proposal Layer负责综合所有[dx(A),dy(A),dw(A),dh(A)]变换量和foreground anchors,计算出精准的proposal,送入后续RoI Pooling Layer。
Proposal Layer的caffe prototxt定义如下:
Proposal Layer有3个输入:
fg/bg anchors分类器结果rpn_cls_prob_reshape,
对应的bbox reg的[dx(A),dy(A),dw(A),dh(A)]变换量rpn_bbox_pred,以及im_info;
另外还有参数feat_stride=16,指的是四次pooling后map缩小为1/16。
Proposal Layer网络的前向过程大致如下:
1.生成anchors ,利用[dx(A),dy(A),dw(A),dh(A)]对所有的anchors做bbox regression回归
注意这里才生成anchors,即生成在原图中anchors的坐标
2.按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
3.利用im_info将fg anchors从MxN尺度映射回PxQ原图,判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors
4.进行nms
5.再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出
ROI pooling
RoI Pooling层负责收集proposal,统一proposals的尺度,送入后续网络。从图2中可以看到Rol pooling层有2个输入
1.原始的feature maps
2.RPN输出的proposal boxes(大小各不相同)
|
|
下面来研究一下caffe的具体实现
Classification
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
Classification部分网络结构如下图
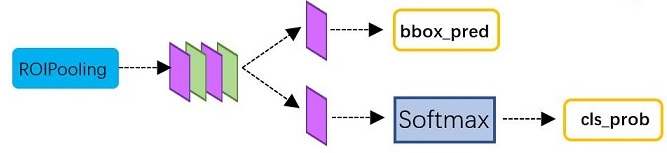
从PoI Pooling获取到7x7=49大小的proposal feature maps后,送入后续网络,可以看到做了如下2件事:
通过全连接和softmax对proposals进行分类,这实际上已经是识别的范畴了
再次对proposals进行bounding box regression,获取更高精度的rect box
Faster RCNN训练
Faster CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。实际中训练过程分为6个步骤:
1.在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
2.利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
3.第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
4.第二训练RPN网络,对应stage2_rpn_train.pt
5.再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
6.第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
可以看到训练过程类似于一种“迭代”的过程,不过只循环了2次。至于只循环了2次的原因是应为作者提到:”A similar alternating training can be run for more iterations, but we have observed negligible improvements”,即循环更多次没有提升了。
训练RPN网络
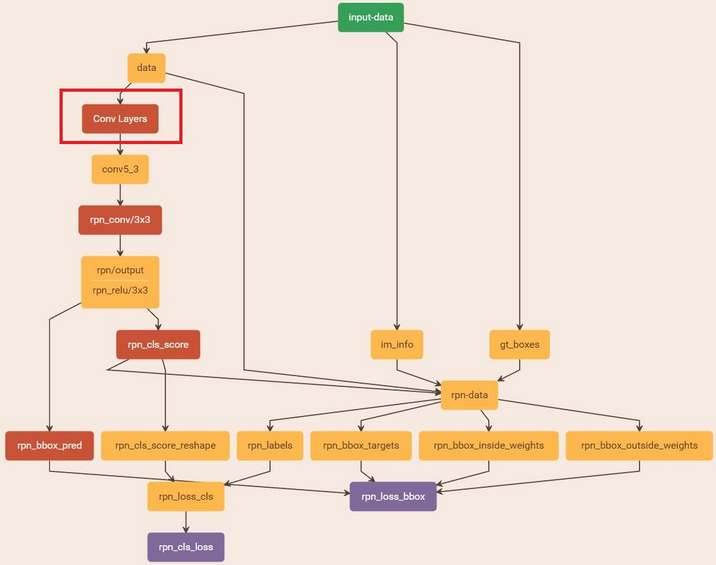
通过训练好的RPN网络收集proposals
在该步骤中,利用之前的RPN网络,获取proposal rois,同时获取foreground softmax probability,如下图,然后将获取的信息保存在python pickle文件中
整个网络使用的Loss如下
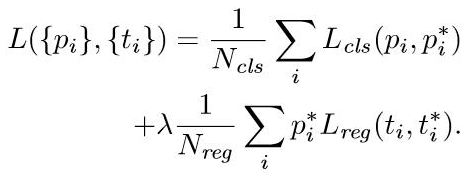
Ncls和Nreg差距过大,用参数λ平衡二者(如Ncls=256,Nreg=2400时设置λ=10)
训练Fast RCNN网络
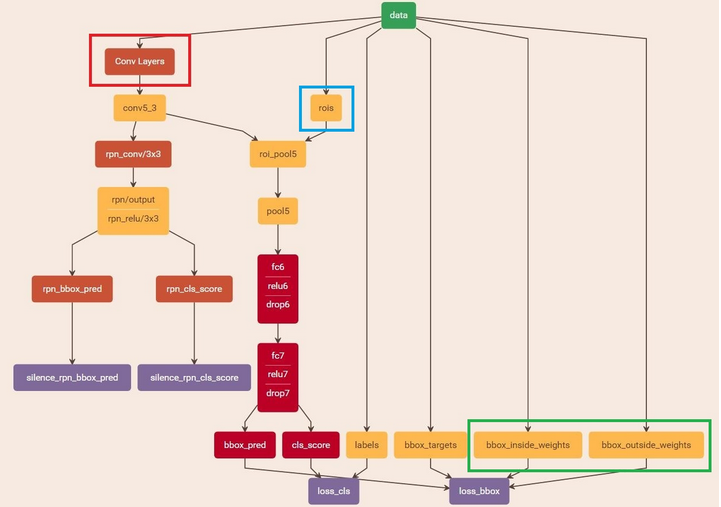
读取之前保存的pickle文件,获取proposals与foreground probability。从data层输入网络。然后:
将提取的proposals作为rois传入网络,如下图蓝框
将foreground probability作为bbox_inside_weights传入网络,如下图绿框
通过caffe blob大小对比,计算出bbox_outside_weights(即λ),如下图绿框
此外,Faster RCNN还有一种end-to-end的训练方式,可以一次完成train